Writing a really general parser is a major but different undertaking, by far the hardest points being sensitivity to context and resolution of ambiguity. Graham Nelson

What is Parsing?
First some definitions:
- lexeme the basic lexical unit of meaning.
- token structure representing a lexeme that explicitly indicates its categorization for the purpose of parsing.
- lexer A algorithm for lexical analysis that separates a stream of text into its component lexemes. Defines the rules for individual words, or set of allowed symbols in a programming language.
- parser an algorithm for converting the lexemes into valid language grammar. Operates on the level above the lexer, and defines the grammatical rules.
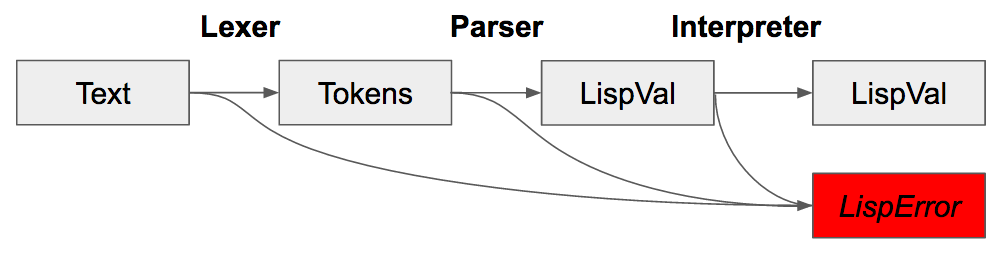
Most basically, Parsing and Lexing is the process of reading the input text of either the REPL or program and converting that into a format that can be evaluated by the interpreter.
That converted format, in our case, is LispVal. The library we will use for parsing is called Parsec.
About Parsec
Parsec is a monadic parser, and matches text to lexeme then parsing that into an abstract syntax via data constructors.
Thus, for text input, the lexemes, or units of text that define a language feature, are converted a LispVal structure (abstract syntax tree).
These lexemes are individually defined via Parsec, and wholly define the valid lexical structure of our Scheme.
Why Parsec?
Parsec is preferable for its simplicity compared to the alternatives: Alex & Happy or Attoparsec. Alex & Happy are more complex, and require a separate compilation step. Parsec works well for most grammars, but is computationally expensive for left recursive grammars. Attoparsec is faster, and preferable for parsing network messages or other binary formats. Parsec has better error messages, a helpful feature for programming languages. If our language required a lot of left-recursive parsing, Alex & Happy would probably be a better choice. However, the simplicity and minimalism of Scheme syntax makes parsing relatively simple. Note A new library has been created from a fork of Parsec called MegaParsec, it takes a monad transformer approach to parsing, and appears quite feature rich and claims to be industry ready!
How parsing will work
The parser will consume text, and return a LispVal representing the abstract syntax tree that can be evaluated into an Eval LispVal.
Parsec defines parsers using,
newtype Parser LispVal = Parser (Text -> [(LispVal,Text)])Thus, a Parser is a type consisting of a function that 1) takes some Text and 2) return a LispVal and some Text
Parser Imports
import LispVal
import Text.Parsec
import Text.Parsec.Text
import Text.Parsec.Expr
import qualified Text.Parsec.Token as Tok
import qualified Text.Parsec.Language as Lang
import qualified Data.Text as T
import Control.Applicative hiding ((<|>))
import Data.Functor.Identity (Identity)Good for us, Parsec is available with Text, not just String. If you are looking online for examples of Parsec, make sure you have the correct encoding of strings.
Converting can be a little bit of a hassle, but its worth the extra effort. If you are really serious about your language project, I suggest using Alex & Happy.
I’ve happily used them in production to parse a javascipt-esque language!
Lexer
lexer :: Tok.GenTokenParser T.Text () Identity
lexer = Tok.makeTokenParser style
style :: Tok.GenLanguageDef T.Text () Identity
style = Lang.emptyDef {
Tok.commentStart = "{-"
, Tok.commentEnd = "-}"
, Tok.commentLine = "--"
, Tok.opStart = Tok.opLetter style
, Tok.opLetter = oneOf ":!#$%%&*+./<=>?@\\^|-~"
, Tok.identStart = letter <|> oneOf "-+/*=|&><"
, Tok.identLetter = digit <|> letter <|> oneOf "?+=|&-/"
, Tok.reservedOpNames = [ "'", "\""]
}Whelp, that’s about all we need. Parsec does the heavy lifting for us, all we need to do is supply the specification for the lexeme. Starting with comments, we’ll use the same standards as Haskell, and moving on to operators and identifiers. Finally, we established reserved operators, which will be single and double quotes.
-- pattern binding using record destructing !
Tok.TokenParser { Tok.parens = m_parens
, Tok.identifier = m_identifier } = Tok.makeTokenParser styleBefore we move on, I’m going to use record deconstruction and pattern binding to define some shortcuts. It’s a neat trick!
Parser
reservedOp :: T.Text -> Parser ()
reservedOp op = Tok.reservedOp lexer $ T.unpack opUsing our shortcut, we can define a quick helper function to lex the input text for reserved operators.
Now, given the diagram, we must move from Text to LispVal.
Parsec will be handling the lexer algorithm, which leaves the formation of LispVal.
You will notice the use of T.pack, which is T.pack :: String -> Text.
For each data constructor of type LispVal, we will have a separate parsing function.
Later, we will combine them into a single parser for all S-Expressions called parseExpr.
parseAtom :: Parser LispVal
parseAtom = do
p <- m_identifier
return $ Atom $ T.pack p
parseText :: Parser LispVal
parseText = do
reservedOp "\""
p <- many1 $ noneOf "\""
reservedOp "\""
return $ String . T.pack $ p
parseNumber :: Parser LispVal
parseNumber = Number . read <$> many1 digit
parseNegNum :: Parser LispVal
parseNegNum = do
char '-'
d <- many1 digit
return $ Number . negate . read $ d
parseList :: Parser LispVal
parseList = List . concat <$> Text.Parsec.many parseExpr
`sepBy` (char ' ' <|> char '\n')
parseSExp = List . concat <$> m_parens (Text.Parsec.many parseExpr
`sepBy` (char ' ' <|> char '\n'))
parseQuote :: Parser LispVal
parseQuote = do
reservedOp "\'"
x <- parseExpr
return $ List [Atom "quote", x]
parseReserved :: Parser LispVal
parseReserved = do
reservedOp "Nil" >> return Nil
<|> (reservedOp "#t" >> return (Bool True))
<|> (reservedOp "#f" >> return (Bool False))Phew! That wasn’t so bad! Monadic parsing makes this somewhat manageable.
We consume a little bit of text, grab what we need with monadic binding, maybe consume some more text, then return our LispVal data constructor with the bound value.
There is one extra parser, parseList. This is used to parse programs since programs can be a list of newline delimited S-Expressions.
Now that we can parse each of the individual LispVals, how would we parse an entire S-Expression with parseExpr?
parseExpr :: Parser LispVal
parseExpr = parseReserved <|> parseNumber
<|> try parseNegNum
<|> parseAtom
<|> parseText
<|> parseQuote
<|> parseSExpOf course! <|> is a combinator that will go with the first parser that can successfully parse into a LispVal.
If you are writing this parser, or don’t like mine and decide to write your own (do it!), this part will require some thought.
Here be dragons, and if your syntax is very complex, Alex & Happy provide a nice alternative way to define syntax.
[Understanding Check]
You just moved to Paris, France and can’t find the “quote” on a local keyboard. Change the “quote” to a “less than” symbol in the parser. (single or double, I can’t find either one on european keyboards) Where do all the changes need to be made?
Move around the ordering in parseExpr, what happens? When do things break?
parseNumber works for positive numbers, can you get it to work for negative numbers?
Parsec Parser is used as both a monad and a functor, give an example of both.
Putting it all together
Parsec needs to play nice with the rest of the project, so we need a way to run the parser on either text from the REPL or a program file and return LispVal or ParseError.
There’s a monad for that!
contents :: Parser a -> Parser a
contents p = do
Tok.whiteSpace lexer
r <- p
eof
return r
readExpr :: T.Text -> Either ParseError LispVal
readExpr = parse (contents parseExpr) "<stdin>"
readExprFile :: T.Text -> Either ParseError LispVal
readExprFile = parse (contents parseList) "<file>"contents is a wrapper for a Parser that allows leading whitespace and a terminal end of file (eof).
For readExpr and readExprFile we are using Parsec’s parse function, which takes a parser, and a Text input describing the input source.
readExpr is used for the REPL, and readExprFile, which uses our parseList and can handle newline or whitespace delimmited S-Expressions, for program files.
Conclusion
From the top, we have gone from text input, to tokens, to LispVal.
Now that we have LispVal representing the abstract syntax tree, we need to get to Eval LispVal, the final computed value.
If you’d like to see the parser in action, run stack test, where the parsing tests are the first block in test-hs/Spec.hs.
Now, it’s time to start running programs, let’s take it to eval and see how LispVal gets computed!
Next, Evaluation
Additional Reading
Monadic parsing is a little tricky to understand. In terms of the rest of programming languages, it’s a somewhat orthogonal subject but nonetheless absolutely necessary to build a programming language!
- https://github.com/bobatkey/parser-combinators-intro
- http://unbui.lt/#!/post/haskell-parsec-basics
- http://dev.stephendiehl.com/hask/#parsing
- http://stackoverflow.com/questions/19208231/attoparsec-or-parsec-in-haskell/19213247#19213247