The most important thing in the programming language is the name. A language will not succeed without a good name. I have recently invented a very good name and now I am looking for a suitable language. Donald Knuth
What do we need to build a Scheme?
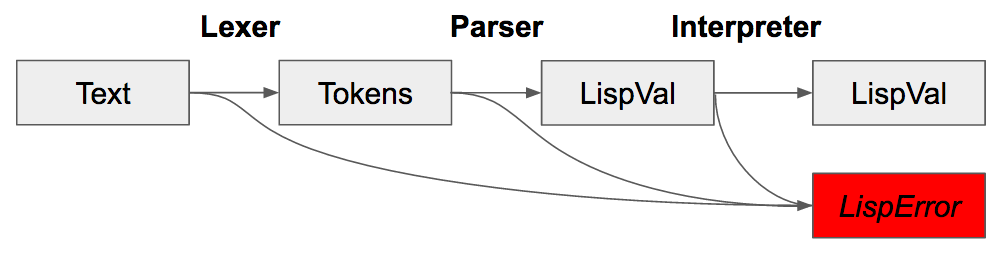
To make a programming language, we must take user inputed text, turn that text into tokens, parse that into an abstract syntax tree, then evaluate that format into a result.
Fortunately, we can use the same structure, LispVal, for the abstract syntax tree, which is returned by the parser and also the result of interpretation.
Homoiconicity for the win!
The lexer and parser are contained in a single library, Parsec, which does most of the work for us.
Once we have parsed into LispVal, we have to evaluate that LispVal into the result of the computation. Evaluation is performed for all valid configurations of S-Expressions, including specials forms like begin and define.
During that computation we need to have an environment for keeping track of bound variables, and an IO monad for reading or writing files during execution.
We will also need a way to convert Haskell functions to internal Scheme functions, and a collection of these functions stored in the Scheme environment.
Finally, a suitable user interface, including Read/Evaluate/Print/Loop, way to run read files/run programs, and a standard library of functions loaded at runtime defined in Scheme is needed.
This may seem like a lot. But don’t worry, all these things, and more, are already available in this project. Together, we’ll go through line by line and make sense out of how these Haskell abstractions coalesce to implement a Scheme!
Project Road Map: What do we have?
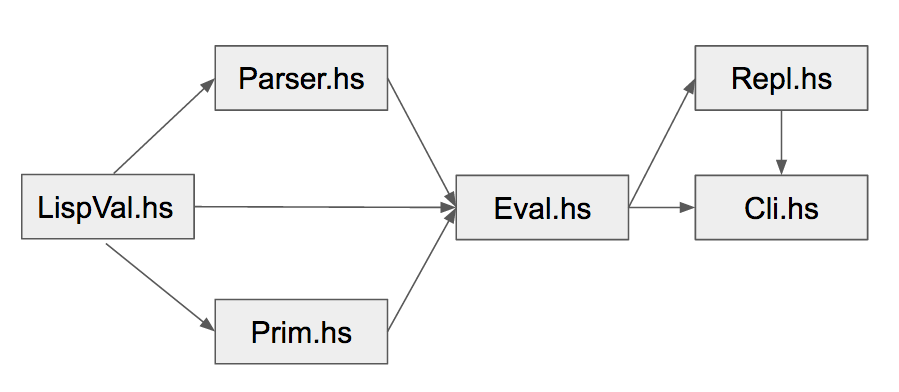
- Main.hs Handles the creation of the binary executable.
- Cli.hs Parsing of command line options, command line interface.
- Repl.hs Read Evaluate Print Loop code.
- Parser.hs Lexer and Parser using Parsec code. Responsibility for the creation of LispVal object from Text input.
- Eval.hs Contains the evaluation function,
eval. Patten matches on all configurations of S-Expressions and computes the resultantLispVal. - LispVal.hs defines LispVal, evaluation monad, LispException, and report printing functions.
- Prim.hs Creates the primitive environment functions, which themselves are contained in a map. These primitive functions are Haskell functions mapped to
LispVals.
An Engineering Preface
Before we start, there is a note I have to make on efficient memory usage Haskell.
The default data structure for Haskell strings, String, is quite wasteful in its memory usage.
There is an alternative, Data.Text, but to get Haskell to parse strings into Text instead of String we must use:
{-# LANGUAGE OverloadedStrings #-}
import Data.Text as TThis declaration will be at the top of every file in the project.
Not every library in the Haskell code base has converted to Text, so there are two essential helper functions:
T.pack :: String -> Text
T.unpack :: Text -> StringHowever, this project uses overloaded strings in all files, and I advocate Text becoming the standard for the language.
This is the “strong” position on Text, and requires that all upstream libraries be written to be either Text agnostic, or work with Text.
This may not always be the case. For these situations, you can convert into Text using T.pack, or just keep using String.
Internal representation, welcome to LispVal
We need a way to represent the structure of a program that can be manipulated with Haskell.
Haskell’s type system allows for pattern matching on data constructors. Our eval function uses this mechanism to differentiate forms of S-Expressions.
LispVal Definition
After much ado, here’s the representation of the S-Expression from LispVal.hs. All code and data is represented by one of the following data constructors. There is nothing else. Let’s take a look!
data LispVal
= Atom T.Text
| List [LispVal]
| Number Integer
| String T.Text
| Fun IFunc
| Lambda IFunc EnvCtx
| Nil
| Bool Bool deriving (Eq)
data IFunc = IFunc { fn :: [LispVal] -> Eval LispVal }Bool, Number and String are straightforward wrappers for Haskell values.
Nil is the null type, and the result of evaluating an empty list.
Atom represents variables, and when evaluated will return some other value from the environment.
To represent an S-Expression we will use List, with 0 or more LispVal.
Now for the trickier part: functions.
There are two basic types of functions we will encounter in Scheme.
Primitive functions like + use Fun. The second type of function is generated in an expression like:
((lambda (x) (+ x 100)) 42)To handle lexical scoping, the lambda function must enclose the environment present at the time the function is created.
Conceptually, the easiest way is to just bring the environment along with the function.
For an implementation, the data constructor Lambda accepts EnvCtx, which is the lexical environment, as well as IFunc, which is a Haskell function.
You’ll notice it takes its arguments as a list of LispVal, then returns an object of type Eval LispVal. For more on Eval, read the next section.
Evaluation Monad
(from LispVal.hs)
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
import qualified Data.Map as Map
import Control.Monad.Except
import Control.Monad.Reader
type EnvCtx = Map.Map T.Text LispVal
newtype Eval a = Eval { unEval :: ReaderT EnvCtx IO a }
deriving ( Monad
, Functor
, Applicative
, MonadReader EnvCtx
, MonadIO)For evaluation, we need to handle the context of a couple of things: the environment of variable/value bindings, exception handling, and IO.
In Haskell, IO and exception handling are already done with monads.
Using monad transformers we can incorporate IO, and Reader (to handle lexical scope) together in a single monad.
Using deriving, the functions available to each of the constituent monads will be available to the transformed monad without having to define them using lift.
A great guide about using monad transformers to implement interpreters is Monad Transformer Step by Step.
It will start with a simple example and increase complexity.
It’s important to keep in mind that evaluation is done for LispVals that are wrapped within the Eval monad, which will provide the context of evaluation.
The process of LispVal -> Eval LispVal is handled by the eval function, and this will be discussed a few chapter ahead.
Reader Monad and Lexical Scope
We use the ReaderT monad to handle lexical scope.
ReaderT is basically a monadic action e -> m a, which in our case is EnvCtx -> IO LispVal.
If you are not familiar with monads, or ReaderT, you can see the definitions here. ReaderT has two basic functions: ask and local.
Within the monadic context, ask is a function which gets EnvCtx, and local is a function which sets EnvCtx and evaluates an expression. As you can imagine, we use ask to get the EnvCtx, Map.lookup and Map.insert to either get or store variables, then local to evaluate our expression with a modified EnvCtx.
If this doesn’t make sense yet, that’s okay. There is example code on the way!
Show LispVal
While on the topic of LispVal, we can add some code to nicely print out values in LispVal.hs
Ideally, we will have functions for both LispVal -> T.Text and T.Text -> LispVal.
The latter will be covered in the next section on parsing.
instance Show LispVal where
show = T.unpack . showVal
showVal :: LispVal -> T.Text
showVal val =
case val of
(Atom atom) -> atom
(String str) -> T.concat [ "\"" ,str,"\""]
(Number num) -> T.pack $ show num
(Bool True) -> "#t"
(Bool False) -> "#f"
Nil -> "Nil"
(List contents) -> T.concat ["(", T.unwords $ showVal <$> contents, ")"]
(Fun _ ) -> "(internal function)"
(Lambda _ _) -> "(lambda function)"As you can see, we use case to match data constructors instead of pattern matching the arguments of showVal.
We have no good way to represent functions as Text, otherwise, LispVal and Text should be interconvertible.
This is true before evaluation, or as long as the S-Expression does not contain functions from either data constructor.
This feature is analogous to serialization, and later, when we have parsing, we will have de-serialization.
[Understanding Check]
- What’s the difference between
TextandString? - How do we represent S-Expressions in Haskell?
- What is a monad transformer? How is this abstraction used to evaluate S-Expressions?
- I mentioned
ReaderTgives use -> m afunctionality viarunReaderT, imagine if we wante -> m (e, a). What monad would we use, and how would that affect lexical scoping? - Can you think of some alternative ways to represent S-Expressions? What about GADT? If you would like to see a Haskell language project using GADTs, GLambda is a great project!